Metadata in the Web and How it Helps Search Engines and SEO 🏷️




Stefan Petrov
September 24th, 2021
IT
Wikipedia’s definition of metadata states that metadata is “data that provides information about other data”. If that sounds confusing and complicated don’t worry, because it isn’t. In essence, metadata is data used to explain the main data inside a file, an object, a website, etc. Let me explain it through a simple example.
If you had to find a single person based on their past and life story, you’d spend a long time looking as you’d have to go through over seven billion people. Now imagine if you had to find that same person based on their name, surname, age, etc. It suddenly becomes much simpler, right?
Metadata provides a way to easily organize, structure, sort, and search through data in a simple way. Metadata is often structured in a certain way and the template structure is shared across similar objects, making them easy to sort through and browse. Although there are different types of metadata structures, such as plain text, HTML, XML, RDF and so on, mixing and matching is not common because it makes organization much more difficult.
Metadata on the internet

The internet’s HTML format lends itself extremely well for several metadata types, including basic descriptive text, dates, keywords, Dublin Core, e-GMS, AGLS, etc. Web pages can also be injected with coordinates and they can be geotagged.
In a typical HTML page, metadata is usually inserted into the header, but it can also be linked to if it’s added in a separate file. In the internet’s early years, metadata was invaluable when it comes to search engines and sorting content. It gave search crawlers something to process and define, as there wasn’t any ‘smart’ way of sorting through the actual data on the page itself.
These days Google and similar search engines don’t rely on metadata all that much because of metadata exploitation for the benefits of search engine optimization (SEO). You see, when developers and website owners figured out that they can use metadata to artificially boost their search rankings, they started playing all kinds of dirty tricks just to get a jump on the competition.
Keyword stuffing was one of the most popular techniques to boost search rankings back in the mid-to-late 2000s. Websites would use the keyword metadata field to stuff as many keywords as possible, often cramming keywords unrelated to the actual on-page content just to appear for as many search terms as possible.
Google subsequently rolled out several different updates to ban the practice, rendering the keyword metadata field practically useless nowadays. The practice of using banned or frowned-upon techniques to boost search rankings is called black-hat SEO. These include things like article spinning, using duplicate content, buying links, etc. The consequences of these techniques can be severe.
By contrast, white-hat SEO is a term used for techniques which are actively encouraged by Google and other search engines. These include but are not limited to keyword research, internal linking and on-page optimization. These techniques don’t yield as big of a reward as black-hat ones, but they’re safe and they’re more stable in the long run.
Modern metadata tags
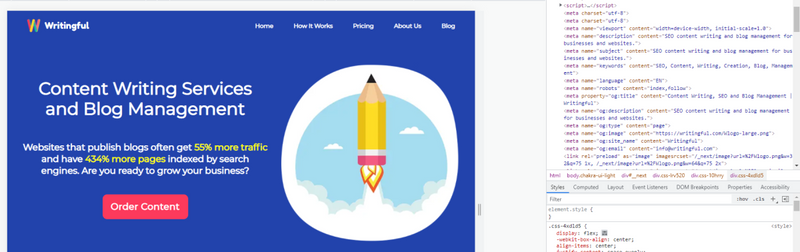
Modern HTML documents use meta tags to describe the page itself. These tags are denounced by the <meta> tag inside the header, and typically have a key-value pair inside, with the ‘name’ field being the key, and the ‘content’ field being the value. Here’s an example:
There are hundreds of meta tags available out there, but they’re not all equally valuable or useful. Most websites use several dozen meta tags to be parsed by the search engine, completely ignoring outdated or unused tags in the modern era.
Apart from the basic HTML tags which are universal for every HTML page, you can also find various other tags for use with social media like Twitter or Facebook (OpenGraph), and you can even create your own custom meta tags. Here’s a list of some of them and a quick description.
HTML Meta Tags
<meta name="keywords" content="your, tags"/>
The keywords tag is practically useless nowadays as almost no search engines places any emphasis on it, but it’s still being implemented by some older websites. If you’re building a new website from scratch, don’t bother with the keywords tag.
<meta name="description" content="150 words"/>
The description tag is one of the most important tags (up there with the title tag in the head), as this is what Google and other search engines use to display as the description in search results. Here’s what I mean:
<meta name="subject" content="website's subject">
Again, this isn’t all that useful or heavily relied on in the modern era, but it can’t hurt to implement it and tell search engines what your page is all about (although they deduct that themselves by analyzing the on-page content).
<meta name="language" content="ES">
As its name would suggest, this meta tag describes the language of the website (or particular page), helping search engines serve relevant content to users in a particular region or searching by a particular language.
<meta name="robots" content="index,follow" />
This is a tag which tells search engines whether to rank the particular page and show it in search results. The ‘follow’ value specifies whether links on the page should be followed and the appropriate credit be given to those external websites. The default is “index, follow”, so even if you don’t specify this tag, search engines will crawl it. Specifying ‘noindex’ is valuable if you’ve got parts of your website which shouldn’t be shown on Google and other search engines (such as dashboard, login page, etc.)
<meta name="revised" content="Sunday, July 20th, 2020, 8:20 pm" />
As implied, this tag tells the search engine when the webpage was last modified. Most websites keep a record of this same information in the sitemap XML file, which shows how the website is structured, shows all the routes/pages, and optionally when they were modified.
<meta name="abstract" content="">
A one-line sentence which should summarize the entire webpage. Not used by search engines as often as it once was.
<meta name="author" content="name, [email protected]">
A meta tag describing the page’s author. Typically used with blogs where each blog can be written by a different author. Common pages use the website info email as an author (provided they choose to use this meta tag at all).
<meta name="designer" content="">
This is a rare meta tag to see nowadays and it’s reserved for the person/company who designed the website. I’ve only seen it a handful of times, and I’m positive it has no impact on search engines other than to give the designer credit in case anyone looks at the tags in the head.
<meta name="copyright" content="">
In today’s day and age, the copyright meta tag can be an extremely valuable tool if you want to give credits to the author/owner or list yourself as the owner. Dublin Core proposes that you use ‘rightsHolder’ instead of ‘copyright’ in the name field for modern HTML5 documents.
<meta name="reply-to" content="[email protected]">
In the ‘reply-to’ meta tag you should list the email of the person responsible for maintaining and operating the website. This can come in handy if someone has questions about the website itself or wants to report an issue. By most accounts this tag is now defunct because of spam robots which harvest email addresses.
<meta name="owner" content="">
A meta tag responsible for listing the owner of the website. Closely related to the copyright tag as it lists the person who owns the website, but the two don’t necessarily have to overlap as the website can also host pages/content which are the property of a third-party.
<meta name="url" content="http://www.websiteaddrress.com">
A link to the current path of the website, typically useful if the website uses multiple URLs for the same page but only one is canonical. For instance, if the URL has a string query, the ‘url’ meta tag can be helpful in determining the original path (although search engines by and large do this on their own).
OpenGraph Meta Tags
These are meta tags used by Facebook, LinkedIn and Twitter (assuming Twitter Cards are not available). They’re designed using the Open Graph protocol and their common denominator is the ‘og:’ tag in the beginning of the property field.
The difference between these tags and the basic HTML tags is that the OG tags were specifically designed for social media platforms in mind. They make content more eye-catchy in social media feeds and they help Facebook and other platforms understand what the content is about much better.
Custom Meta Tags
You can create custom meta tags if you use third-party services or even if you need them for your own benefit. They’re most commonly used to store data that you’ll need in JavaScript instead of hard-coding it into the JS code itself.
Conclusion
This is not an exhaustive list of all meta tags, but a subset of the most commonly used ones. We didn’t cover the Apple meta tags or the Internet Explorer meta tags (most of which are now defunct). To build a modern website though, the tags listed in this article are more than enough to get the site ranking and showing properly in all search engines and even in most social media platforms.


Did you enjoy this article?
If you did and want to order similar content for your own website, click the button below. We cover most industries and topics. If you have any questions, don't hesitate to contact us at [email protected]


About the author
Stefan is the founder and owner of Writingful. He's been working as a freelance writer for over 6 years, writing about anything and everything. His expertise lies in the Automotive industry, SEO and IT. He even built Writingful using Next.js and Sanity.io.
Services
Content Writing
Blog Writing
27 Old Gloucester Street
London, United Kingdom
WC1N 3AX
Privacy Policy
Terms of Use
© 2021 Writingful.
All Rights Reserved.